A real-life machine learning journey
Say you have a Governance, Risk and Compliance (GRC) platform up-and-running already for several years, supporting many different processes, and holding a lot of data for over 8000 active users worldwide. Say “Innovation” is part of the platform roadmap and one of the topics is Machine Learning (ML). Let the fun begin.

Approach of the project
You might have heard the quote from Donald Knuth “premature optimization is the root of all evil”. With this in mind, we approached our project. You might think that for any serious ML project you need an army of data scientists and machine learning engineers. If you have the right expertise, this is certainly not the case. Usually an ML engineer, architect and a front-end developer are sufficient. And a focus on business problems and involvement from the business.
We started our journey with a small team consisting only of the Product Owner of the GRC platform and myself, supported by the Rabobank AI/ML lead of the Compliance domain. Together with the business we identified various use cases. Of those identified, we selected and implemented a lower complexity but value adding use case. This was our start. Remember the quote.
Using Rabobank’s ML platform (BigML), we successfully built a Proof of Concept (PoC) within 1.5 months. Working on the solution on average about a day a week. The use case was running in Production in 3 months.
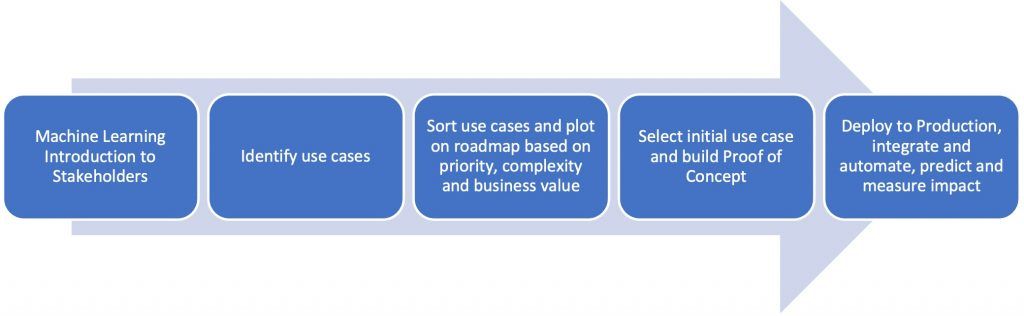
Use case ML project
As with every ML project, domain knowledge is very important. Let me give you a bit of background on the use case. Rabobank receive an ever-increasing amount of regulatory content from various external data providers and issuing authorities. On average 450 new items per month are received for which it must be determined whether Rabobank needs to take action in order to prepare and/or remain compliant in the area of laws and regulations. Normally, the determination of the relevance of data, which ultimately accounts for about 25% of these 450 items, is performed by a human decision maker supported by manually created business rules.
Table 1 provides an overview of the three classes an item can be assigned to.

In summary, a lot of data is received every month and while the manually created and maintained business rules are very useable, they take a lot of time to maintain, become increasingly complex and most likely less accurate over time.
This is where ML comes into play.
Building the machine learning solution
What we are looking at is a supervised learning task. And more specifically, a classification task. Supervised, because we teach the ML algorithm what is the correct answer (the data we already labelled, or classified, ourselves in the past). Classification, because our goal is to classify new instances (records, or rows in a table).
While my hands were itching to get started on the actual ML, it’s always good to define when the ML solution is a success. We created a research question that includes all important aspects:
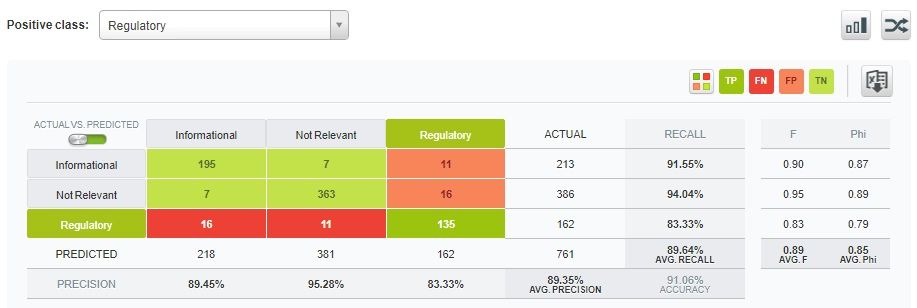
Can we determine the Relevance Class (what we try to predict) based on the raw Content Provider data (what data we use) with a recall of at least 75% and a precision of at least 70% for the "Regulatory" class (what the performance metrics are and when the ML solution is considered to be a success)?
Now that we had our research question in place, it was time to get our hands dirty. It would be too easy if we could just load the data into the ML algorithm and be done with it wouldn’t it? Naturally, we ran into things you usually run into with real projects and real data. To name a few, data quality issues, missing data, difference in content from different content providers.
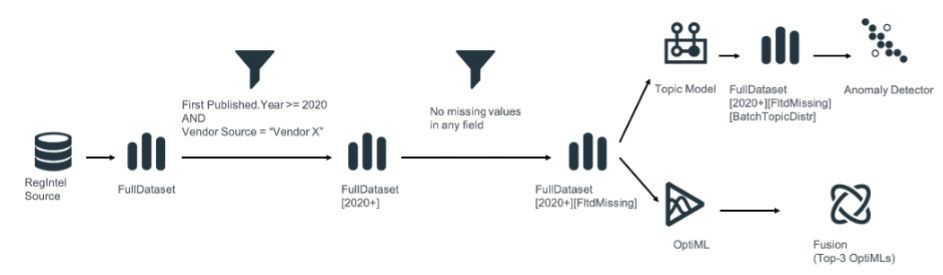
So, we first needed to select the data and prepare it. Preparing includes cleaning, filtering, combining, and dealing with text (using Natural Language Processing, or NLP). The result is a set of features that can be presented to the ML algorithms. Which is, of course, exactly what we did. Using an OptiML, we let BigML find the best performing models using various algorithms with various settings. To top it off, the top-3 models are then “fused” into one model which is used to do the actual prediction.
Will the model we created be useable forever? No, unfortunately not. Data will change over time resulting in a model quality decrease. We could retrain our model periodically. However, we chose to create an anomaly detector which provides each data point with an anomaly score. The higher the anomaly score, the more anomalous that data is. A low score tells us that the model recognises the data it has been presented with, while a high score tells us the opposite.
Figure 3 shows the full process to build to a model and anomaly detector.
The evaluation results are shown in Figure 4. Not bad, eh?
So now we are done, right?
Well, not exactly. There is more to a ML solution than a ML model. We need to think about other things too. In the GRC platform, directly after importing new data, we were able to setup automation to retrieve the predicted classes for the new data. To monitor the model performance, reports have been built in the GRC platform to show the confidence and anomaly scores by month. In BigML, a script has been written to automatically kick off the ML training workflow to generate a new model and anomaly detector with new data.
What’s next?
Remember the quote I used earlier? “Premature optimization is the root of all evil”. Building an ML solution is (or should be) an iterative process. We deliberately started small with plenty of room for improvement. Just to name a few:
- the data quality can be improved,
- instead of the abstract of the regulatory intelligence we could use the full text (which requires additional effort)
- retraining of the model could be fully automated
Also, this blogpost only discusses one use case. There are many others that can be supported by ML. The idea of this first use case is to let it prove itself and open the doors for many more.